

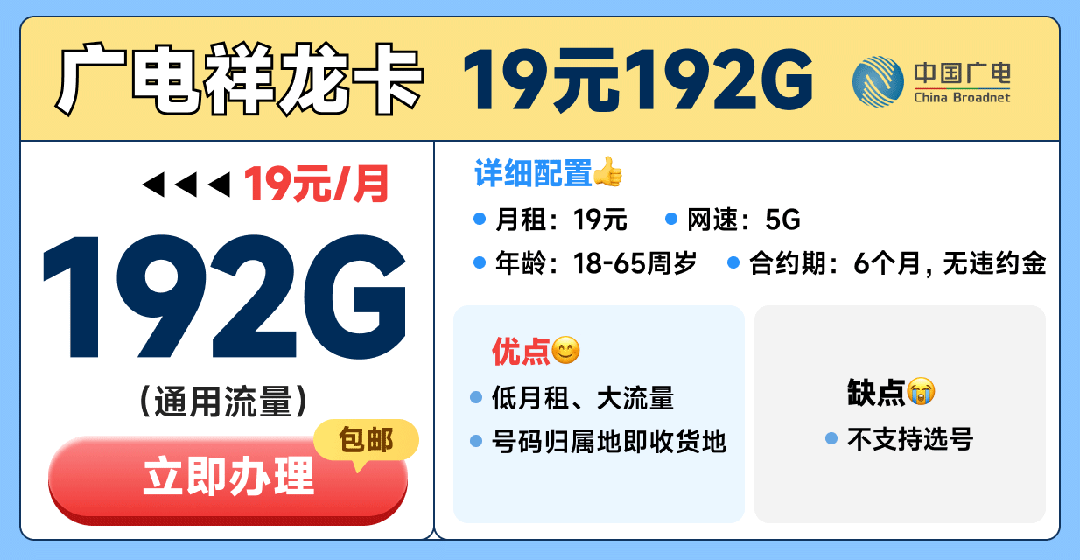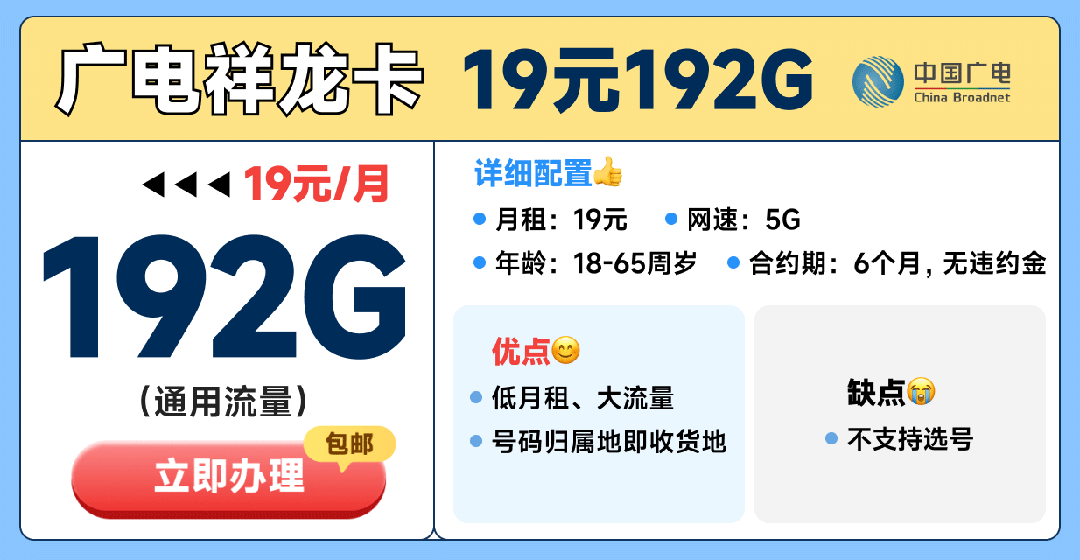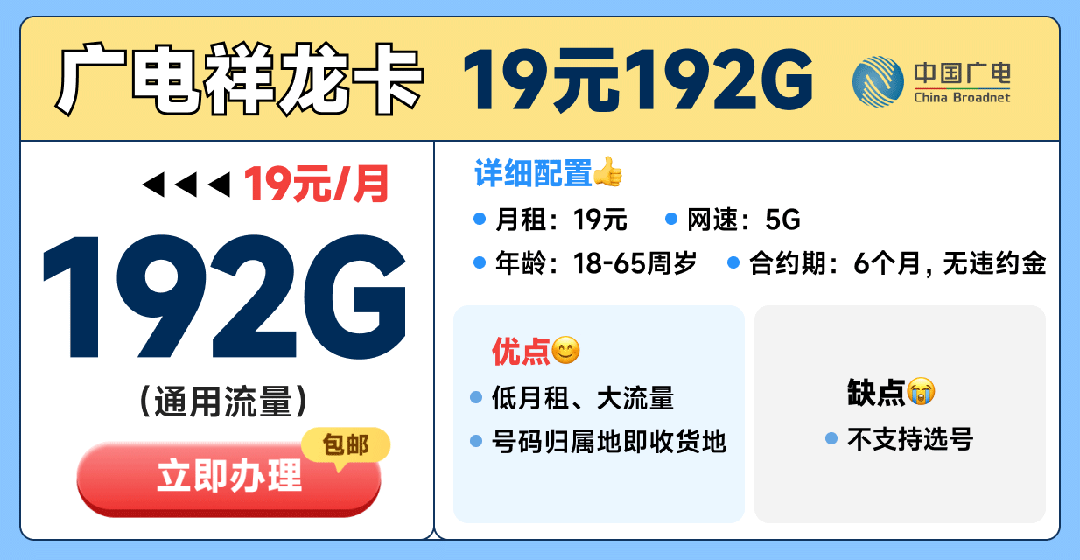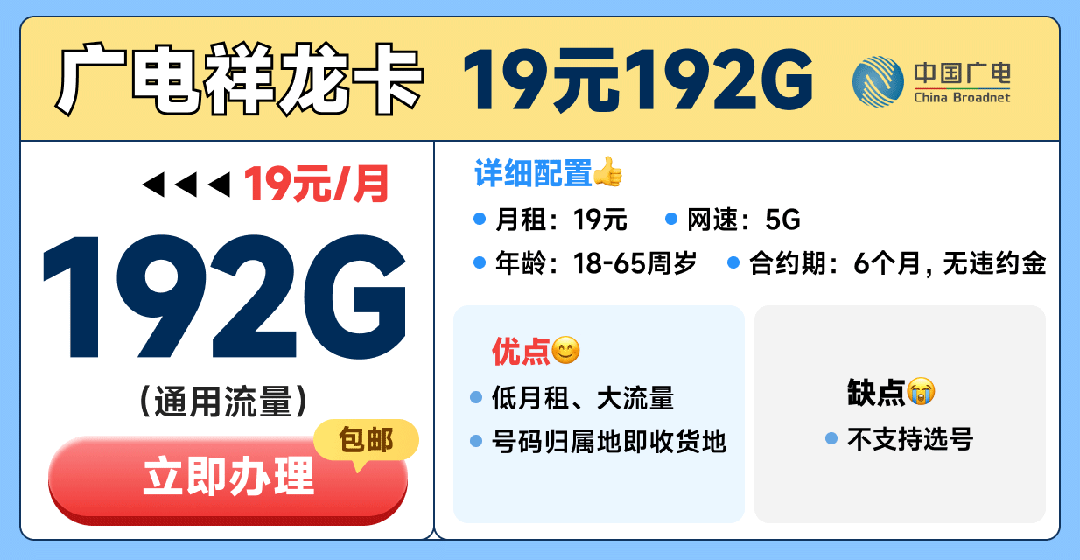
分布式和集群是兩種不同的計算架構,它們的主要區別在于處理數據的方式、系統的可擴展性和性能。
1、數據處理方式:在分布式系統中,數據被分割成多個部分,分布在不同的節點上,每個節點獨立地進行計算,然后將結果匯總,這種方式使得系統具有較高的可擴展性,因為可以通過增加節點來提高計算能力,而在集群中,所有節點共享相同的硬件資源,如CPU、內存和存儲,集群通過協調各個節點的工作來完成任務,但單個節點的故障可能會影響整個系統的性能。
2、可擴展性:分布式系統具有良好的可擴展性,可以通過增加或減少節點來適應不斷變化的計算需求,而集群的可擴展性相對較差,因為需要重新分配硬件資源和管理網絡連接,集群中的節點可能需要同步數據和狀態,這會降低系統的性能。
3、性能:分布式系統通過并行計算和負載均衡來提高性能,每個節點只負責處理部分任務,從而提高了計算效率,而集群中的節點需要協同工作,可能會導致性能瓶頸,由于集群中的節點共享硬件資源,因此在高負載情況下,可能會出現資源競爭和性能下降的問題。
4、應用場景:分布式系統通常用于處理大量數據的分析和計算任務,如大數據、機器學習和人工智能,而集群更適用于需要高性能計算和復雜任務處理的應用,如科學研究、金融交易和工程設計。
分布式系統和集群在數據處理方式、可擴展性和性能等方面存在差異,分布式系統具有更高的可擴展性和性能,適用于處理大量數據的計算任務;而集群則更適用于高性能計算和復雜任務處理。
發表評論